Welcome to the first AI SEO Benchmark update. I don’t like fluff, so I’ll try and make this the most useful thing you read on AI + SEO today.
What is this and why are you doing it?
Like everyone in the world, we are asking ourselves – will AI be good enough to do my work? Is it reliable for tasks that I do every day? There is SO much hype – When is it the right time to change my investments on digital marketing or SEO?
So we looked to industries that are already benchmarking AI performance for expert-level knowledge work. Sites like livebench.ai do a great job of establishing a benchmark that they can run models against to see how models progress and which ones perform well in which discipline.
As an agency with veteran SEOs we established a benchmark as well. We consulted with AI engineers and data scientists to create a framework we feel is fair and representative. The interesting caveats are these:
- SEO is largely a self-taught discipline
- Many of the experts learned what NOT to do and often don’t post their failures publically
- Most see SEO as a tactic best kept as a secret
Each of these wrinkles make it more interesting to see how LLMs might perform given that the task they’ll need to do every day aren’t necessarily repeatable and widely written about.
Results – The AI SEO Benchmark
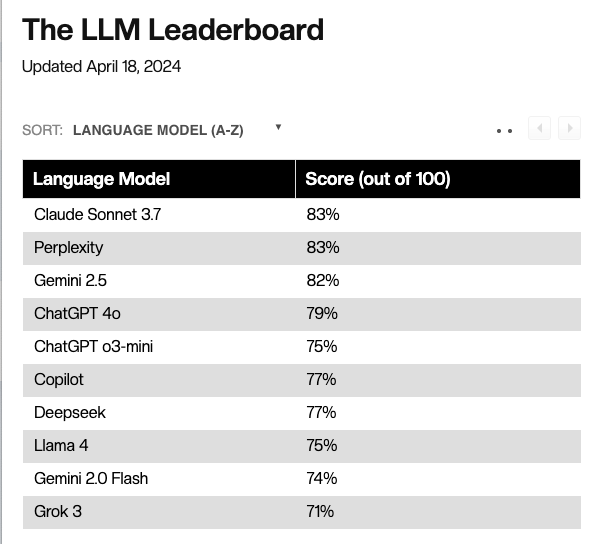
Takeaways:
- Claude was by far the most impressive language model out of the gate. It performed the best across the board in additional modes we ran (see ‘features’ section)
- Perplexity and Google seem like logical winners in this benchmark given that their developers are focused on search.
- Meta’s Llama and X’s Grok do not appear to be that useful for answering SEO questions (sorry to SEO twitter RIP)
The above graph will be updated here as new LLM models are released. What follows below was a deeper study that we will not be included in the public benchmark. What follows is a more digestible narrative on the further research our team performed.

We have ourselves an AI model baseline. How does that compare with working with a [human] SEO?
LLMs versus Human SEOs
Here’s the interesting thing —
The average SEO on our team scored 89%.
The beauty of a standardized test is that it’s easy to get clean scores out of a hundred. It’s an area that I think LLMs ought to excel at. That’s exactly what they’re designed to do – predict the next token that’s most likely.
Our team, however, was hired for their expertise in a specific area – Strategy, Content, E-commerce, Localization, Tech, Link building, etc. It’s not our expectation that a content team member be an expert at site migrations and why the 89% makes sense. The other piece is that we have up to 4 domain experts on every engagement we work on to ensure we have consensus across disciplines.
We’re not even talking about the other areas of SEO, like building a business case and managing the work to see it to completion. A single individual who can do everything SEO is a ‘diamond in the rough’. That’s why we build our teams to have a diverse group to validate and support SEO programs.
I give Claude Sonnet 3.7 high marks for being pretty well rounded in performance when answering SEO questions. Heavy emphasis on ‘answering SEO questions‘ please keep in mind that none of these tools execute changes (at least currently). Not to be an AI skeptic, I just want to be clear that AI agents do not currently exist to reliably execute broad tasks. Trust me, I’ve tried. This one is the most interesting but still goes rogue when trying to order UberEats.
Where I am a skeptic is LLM reliability across categories of SEO. So with that said, let’s dig into what where LLMs excel for SEO and the areas to avoid using them.
LLM SEO Performance by Category
LLMs tend to do quite well with content. That seems like a no-brainer. They scored on average 85% in that area. If you’re going to use LLMs in your content process, that’s generally a safe bet. Definitely don’t go wild by generating everything with AI; it won’t work. You need to create quality content that is aligned with Google’s guidance on AI-generated content. Where your team needs to be thinking is what new proprietary and valuable experiences you can create for users.
On the other hand, please don’t let ChatGPT do your next tech audit or site migration. LLMs on average scored 79% on tech tasks. This was a bit surprising considering many LLMs are hyped for their quality coding abilities.
That’s not the worst of it. The average LLM score for E-Commerce SEO was 63%… Yikes.

For the time being, it is not a good idea to overly rely on LLMs for tech or e-commerce SEO.
It wouldn’t be one of my posts if it didn’t go down at least a few rabbit holes. Ooh I see a rabbit!
Features
All LLM chatbots have features, many of which were copied from each other. There’s also quite a bit of hype over deep research and web search. Let’s take a look at some of the most common features and how those impacted their performance on the AI SEO Benchmark.
- Adding a Persona – If you add “you are an SEO expert” at the beginning of a prompt, does it make it perform better?
- Yes. 2.8% better on average

- Web search – By allowing LLMs to use web search, will it find better or more timely resources to answer your SEO questions?
- No. -3.2% worse on average
- Deep research – A newer and hyped feature to allow LLMs to ‘think’ for a long time to better respond to your answers through chain of thought reasoning.
- No. -5.7% worse on average
This was the most surprising result from the study. The most hyped features make the LLMs perform worse. I can write an entire blog post on the implications.
How Does this Impact your SEO program Today?
In my opinion, LLMs have a fundamental problem – they are probabilistic. It’s the same reason why you see Apple delaying it’s AI integrations for years. If you were to ask Siri to set your alarm to wake up at 7AM to not miss your flight and it got it right 83% of the time, you would NEVER use it.
Until they are 99%+ reliable, it’s impossible to rely too heavily on them. Your best bet is using them for what they’re good at – like building content briefs or identifying internal link opportunities using embeddings. There are plenty more but those are two out of the box things you can use today.
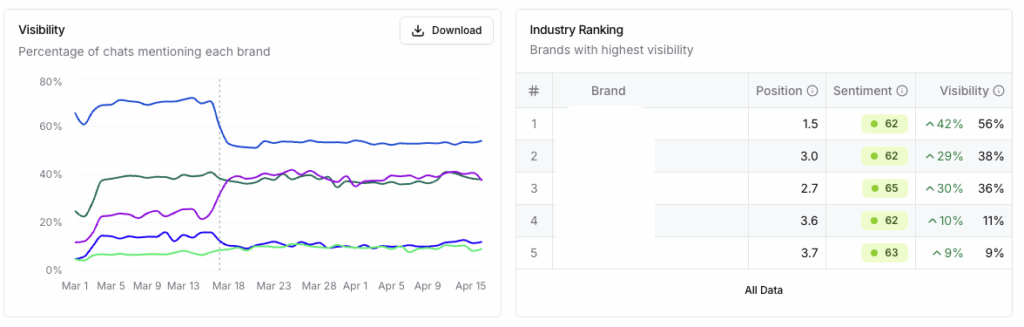
You also need to start tracking your visibility in LLM outputs. For that, we recommend Peec.ai. They’re building a robust tool to help you understand how visible your brand is for important topics from LLM outputs over time. You can see what content gaps you have versus competitors and the most linked resources that are important to your category. Armed with that information, you can build your content roadmap and PR outreach strategy.
Looking to the Future
The AI SEO Benchmark was designed to keep a pulse of how LLMs are advancing. Bookmark it and check back with us while we monitor the progress of AI for SEO. With all of the hype, we’ll try and determine what’s true about AI and it’s impact to SEO and digital marketing.
Keep experimenting to see what works for you and hit me up in Linkedin with your thoughts and ideas!

As co-founder of Previsible SEO, David combines data-driven insights with scalable processes to transform complex marketing initiatives into predictable growth engines.
Ready to rank higher and attract more customers?
Let's chat to see if there's a good fit
More from Previsible




SEO Jobs Newsletter
Join our mailing list to receive notifications of pre-vetted SEO job openings and be the first to hear about new education offerings.